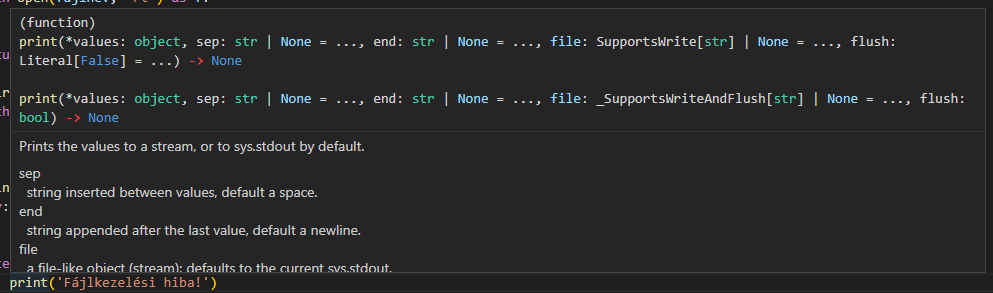
Python 3.5 felett megmondhatjuk a paraméterek típusát és a függvények visszatérési értékét. Ezt a futtatáskor a Python SEMMIRE nem használja, de a fejlesztőrendszerek ellenőrzésre igen. Egyrészt tudnak adni segítséget, másrészt a háttérben folyamatosan tudják ellenőrizni a begépelt kódot.
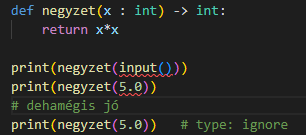
Láthatjuk, hogy ez viszonylag egyszerű. Kettőspont után írjuk a típust, a függvény visszatérési értékét pedig a -> operátor után. Ha ezt megtettük és a fejlesztőrendszerünkben bekapcsoltuk a típusok ellenőrzését, akkor a fejlesztőrendszer figyelmeztetni fog a hibára és kijavíthatjuk, vagy ignorálhatjuk. Ezzel megúszunk olyan bosszantó eseteket, amikor egy elmaradt típus konverzió egy hosszabb futás eredményét esetleg tönkreteszi. Vigyázat, ha bekapcsoljuk lehet, hogy mérgesek leszünk a túlzott precizitástól!
További részletek a kézikönyvben.
Egy programban numerikus integrálásokat kell végeznünk különféle függvényekre. Például tudni szeretnénk,
mennyi a math.sin(x) határozott integrálja [a, b] intervallumon, vagy mennyi a negyzet(x)
függvény integrálja [a, b] intervallumon. Ezeket a határozott integrálokat közelíthetjük téglalapok területösszegével:
apró lépésekben kiszámítva mindenhol a függvények értékét, a téglalapok területét, és azok összegét. Fontos megjegyzés: ez az algoritmus
demonstrációs célokat szolgál. Integrált NEM SZABAD ezzel a módszerrel számolni, erre vannak sokkal jobb algoritmusok, kérdezze meg
matematikusát vagy kedvenc keresőjét...

def integral_sin(a, b):
ossz = 0.0
x = a
while x < b:
ossz += math.sin(x) * 0.001
x += 0.001
return ossz
def integral_negyzet(a, b):
ossz = 0.0
x = a
while x < b:
ossz += negyzet(x) * 0.001
x += 0.001
return ossz
def negyzet(x):
return x ** 2Észrevehetjük, hogy lényegében megírtuk kétszer ugyanazt a függvényt. Mindkettőben ugyanaz az
a-tól b-ig menő ciklus van, mindkettő ugyanúgy lép, ugyanúgy kiértékeli a függvényt, ugyanúgy összegzi a
területeket. Az egyetlen különbség a két integráló között az, hogy mely függvénynek az integrálját számítják ki, vagyis hogy mely
függvényt kell meghívni a téglalapok magasságának meghatározásához.
Felmerül a kérdés, hogy nem lehetne valahogy ezt a kódduplikációt megszüntetni? Nem lehetne az integráló függvénynek paraméterként adni azt, hogy mely matematikai függvénynek határoznánk meg az integrálját?
Ezek alapján már az integráló függvényünk könnyen parametrizálhatóvá tehető:
import math
def integral(f, a, b):
ossz = 0.0
x = a
while x < b:
ossz += f(x) * 0.001
x += 0.001
return ossz
def negyzet(x):
return x ** 2
def main():
print(integral(negyzet, 5, 10)) # !
print(integral(math.sin, 5, 10))
main()Az integrálónak így három paramétere van: az integrálandó függvény: f, és a határok: [a,
b]. A területek számításánál pedig mindig a paraméterként kapott függvényt hívja, f-et. Ez az f
paraméter a két példában más-más függvénynek referenciája; először a saját negyzet()-ünknek, másodjára pedig a
beépített math.sin()-nek. Mivel ez paraméterré vált, az integráló innentől bármilyen más függvényt is tud integrálni,
lényeg, hogy egyváltozós, valós→valós függvényről legyen szó.

Ha ezek megvannak, a megoldások előállítása a permutációk végigpörgetéséből, és azok vizsgálatából áll.
A permutációk előállítása egy rekurzív algoritmussal történik. A rekurzív algoritmus gondolatmenetét egy négyelemű listán szemléltetjük: [1, 2, 3, 4]. Ennek permutációi négy csoportba oszthatóak:
- [1, x, x, x], az egyessel,
- [2, x, x, x], a kettessel,
- [3, x, x, x], a hármassal,
- [4, x, x, x], a négyessel kezdődő permutációk.
Az x-szel jelzett helyeken pedig a többi elem van. A többi elemet szintén sorba lehet rakni különféle módokon. Pl. a [1, x, x, x] esetben ezek a [2, 3, 4], amelyek lehetséges sorrendezései: [2, 3, 4], [2, 4, 3], [3, 2, 4] stb. Ezek pedig előállíthatók rekurzívan, hiszen itt egy háromelemű lista permutációit keressük.
A permutációk előállításának algoritmusa tehát az alábbi:
Permutáció
- Menjünk végig a sorozaton. Tegyük mindegyik elemét az elejére.
- Az így kapott sorozat fennmaradó részét permutáljuk.
- Tegyük vissza az elemet a helyére.
Másképp fogalmazva: előreveszünk egy elemet, kavargatjuk a többit. Aztán előreveszünk egy másik elemet, és megint kavargatjuk a többit. Ezt kell megcsinálni mindegyik elemmel.
def permutal(lista, honnan=0):
if honnan == len(lista): # !
print(lista)
return
for i in range(honnan, len(lista)):
csere(lista, honnan, i)
permutal(lista, honnan + 1) # !
csere(lista, honnan, i)A rekurzív hívásban mindig csak a lista fennmaradó részét kell permutálni, ezért a lista mellett átveszünk
egy honnan nevű paramétert is. A cserék innen indulnak, a rekurzív hívásban pedig honnan + 1
lesz a következő paraméter (a fennmaradó rész). Amikor eljutunk a honnan == meret értékig, akkor előállt
egy permutáció, tehát ez a báziskritérium. Úgy jutottunk oda, hogy közben valamilyen sorrendbe át lett rendezve
a számsor, ezért a programnak abban a pontjában használhatjuk fel az eredményt – jelen esetben csak kiírjuk a számsort.
A rekurziót honnan = 0-val kell indítani; ezt legegyszerűbb úgy megoldani, hogy annak a paraméternek
egy alapértelmezett értéket adunk. Így a permutal(szamsor) hívás lehetséges, és permutal(szamsor, 0)-t
jelent.
Látható, hogy a ciklus az első iterációban nem cserél semmit; akkor épp i == honnan a ciklusváltozó értéke.
Gyakran azt a kódrészletet így szokás írni, hogy ne cserélje meg saját magával feleslegesen a listaelemet:
permutal(lista, honnan + 1)
for i in range(honnan + 1, len(lista)):
csere(lista, honnan, i)
permutal(lista, honnan + 1)
csere(lista, honnan, i)De jelen esetben ennek nincs jelentősége.
A visszalépő keresés alkalmazásai:
- Rejtvények: nyolc királynő, sudoku, keresztrejtvény, labirintus
- Nyelvi elemzés (fordítóban)
- Optimalizálási feladatok, pl. hátizsák-probléma, pénzosztás

Lássunk néhány példát a visszalépő keresés alkalmazására!
Nyelvi elemzés. A fordítóprogramnak a megkapott forráskódot elemeznie kell, és az elemzés közben könnyen zsákutcába
futhat. Például az x--y kifejezés értelmezésekor rá kell jönnie, hogy kerülhet egymás mellé két - karakter.
Ha megpróbálja egy operátorként értelmezni (mint pl. -= is két karakterből áll), akkor zsákutcába jut, Viszont
ha megáll ott, hogy az első - egy kivonás, akkor a második - is kaphat értelmet: ellentettképzésről
van szó. A teljes kifejezés jelentése: x - (-y).
Optimalizálási feladatok. Ezek közül a legismertebb a hátizsák-probléma, amit a rajz is szemléltet. Adott egy hátizsák, amelynek a teherbírása véges. Adott egy csomó tárgy, amelyeknek ismerjük az értékét és a súlyát. Kérdés, mely tárgyakat kell kiválasztanunk, hogy a legnagyobb összértéket állítsuk össze, figyelembe véve a hátizsák teherbírását. A rajz példáját tekintve, a két legértékesebb tárggyal 10+4 = 14 dolláros csomagot állíthatnánk össze, ezeknek a súlya azonban 12+4 = 16 kg, ami túllépi a limitet. Valamelyiket el kell hagynunk, és könnyebbet keresni helyette.
Szintén visszalépő kereséssel oldható meg helyesen egy bankautomata feladata is, amelynek ki kell adnia egy adott összeget, figyelembe véve, hogy milyen címletekből mennyi áll rendelkezésre. Ha a bankautomata rekeszei ezeket a bankjegyeket tartalmazzák:
| címlet | darabszám |
|---|---|
| 5000 | 137 |
| 2000 | 275 |
| 1000 | 0 |
Akkor egy mohó algoritmus, amely a legnagyobb címletekkel próbálkozik a 6000 forint kifizetéséhez nem tudna megoldást találni. Elakadna ott, hogy ad egy 5000-est, és utána 1000-esből meg nincsen. Viszont ezen a ponton visszalépve, úgy döntve, hogy mégsem ad ki 5000-est, rájöhet, hogy a 3×2000 megoldása a feladatnak.